
.avif)
Running production-scale inference workloads is a significant data center scale challenge, requiring optimizations across the entire AI infrastructure stack. When that optimization breaks down, performance suffers, leading to slow user experiences, higher compute costs, and unpredictable reliability, thus slowing down AI innovation and increasing TCO. By establishing the Exemplar Cloud in 2025, NVIDIA provides a standard benchmark for cloud providers to validate their infrastructure performance.
Today, CoreWeave has become one of the first cloud providers to become an NVIDIA Exemplar Cloud for Inference on NVIDIA GB200 NVL72. CoreWeave demonstrated extraordinary inference throughput and latency results, achieving NVIDIA’s high performance standards based on its reference architecture.
This follows our recent milestone as one of the first cloud providers to achieve NVIDIA Exemplar Cloud for Training on NVIDIA GB200 NVL72. This is further proof that the CoreWeave Cloud not only delivers a highly performant platform for training AI models, but also for serving them efficiently and reliably in production.
Together, being one of the first cloud providers to become an NVIDIA Exemplar Cloud for both training and inference showcases CoreWeave’s vertically integrated stack, with Mission Control offering the operating standard for AI cloud with the most performant environment for the entire AI lifecycle. CoreWeave meticulously engineers every layer of our stack from bare metal infrastructure to inference, bringing out the optimal performance of hardware and software combined. That means CoreWeave Cloud is not only highly tuned for training AI models at unprecedented speeds, but also for serving those models efficiently and reliably in production.
NVIDIA Exemplar Cloud represents a consistent benchmarking framework
NVIDIA Exemplar Cloud provides a standard benchmark for cloud providers to validate workload performance in the cloud. Every participating provider undergoes a comprehensive evaluation process designed to reflect real-world customer needs for highly complex and demanding AI workloads. Becoming an Exemplar Cloud requires the ability to demonstrate high performance and resiliency across a suite of open, workload-specific benchmarking recipes covering inference, fine-tuning, and scaled pretraining. The result: a transparent comparison of performance that is validated using the same criteria. With this consistent benchmark data, AI pioneers can reap the following benefits:.
- Predictable, consistent AI workload performance on NVIDIA‑accelerated cloud infrastructure, validated through joint testing and benchmarks
- Confidence in a tuned, optimized infrastructure stack through co‑engineering and ongoing performance validation with NVIDIA
- Objective benchmark data to guide which cloud environments to choose, grounded in real application performance measurements, not vendor claims
The results demonstrate how CoreWeave’s approach to GPU performance with full stack observability via Mission Control and automated performance optimizations consistently yields peak performance and reliability. This means AI pioneers have the ability to deploy large-scale training, disaggregated multi-node inference, or anything in between, with the confidence that their jobs will run effectively and efficiently. This minimizes guesswork and consistently gives them access to new GPUs, providing the predictability, reproducibility, and performance AI pioneers need as they evolve models, scale training, and run inference in production.
CoreWeave achieves NVIDIA’s inference benchmark targets
NVIDIA’s Inference benchmarks test DeepSeek-R1, Llama 3.3, and GPT-OSS models in single and multi-node configurations and measure inference throughput and latencies for common agentic use cases. The number of NVIDIA GB200 NVL72 GPUs was specified by NVIDIA along with TRT-LLM or SGLANG as the backend. The throughput test also included NVIDIA Dynamo for multi-node, which is a high-throughput, low-latency distributed inference model.
For each test scenario, the benchmark evaluated five distinct phases of inference: Reasoning, Chat, Summarization, Generation, and Disaggregation with input and output context lengths. Each is designed to stress-test specific architectural areas to ensure comprehensive coverage within the stack. Metrics used were TPS/GPU (Tokens-Per-Second/GPU) for throughput, and milliseconds for Time-to-First-Token (TTFT) latency. Each test name is followed by (input context length/output context length) below:
- Reasoning (1k/1k): This test used 1K input and 1K output context lengths with long prompts and completions reflecting Chain-of-Thought processing.
- Chat (128/128): Evaluates responsiveness of interactive applications such as chat, prioritizing ultra-low latency and high user concurrency.
- Summarization (8k/512): Tests the I/O and memory bandwidth required to ingest massive prompts before generating a concise output.
- Generation (512/8k): Measures the raw throughput and efficiency of the generation phase, where the model must maintain high speed over a high volume of continuous token production.
- Disaggregation (8k/1k across nodes): Evaluates the efficiency of disaggregated inference, where the prompt processing and token generation phases are split across different GPU nodes.
Throughput tests were conducted using DeepSeek-R1, Llama 3.3, and GPT-OSS in single node configuration with one to four NVIDIA Blackwell GPUs and multi-node with NVIDIA Dynamo using 32 NVIDIA Blackwell GPUs. CoreWeave met or exceeded each of the test scenarios across the five distinct phases described above.
While throughput measures the ability to process and complete the phases of inference of the cluster, TTFT latency measures the speed of the individual unit. In the era of agentic AI, where a single user request might trigger ten sequential model calls, latency becomes the primary constraint on responsiveness. If a model takes too long to process or generate its first word, the user experience suffers, and autonomous agents prove themselves to be too slow to act in dynamic environments.
The latency tests are designed to measure the system's responsiveness. Rather than loading the GPUs to see how much they can handle, these tests measure how fast a single request can move through the stack under optimal conditions. The tests were conducted with DeepSeek-R1 and Llama 3.3 in single node configurations with four GPUs. CoreWeave again met or exceeded each of the test scenarios across the five distinct phases.
Deep dive into CoreWeave’s inference results
CoreWeave’s inference performance advantages were driven by our vertically integrated stack designed specifically for AI workloads. From compute, storage, networking, to orchestration, CoreWeave’s architecture is purpose built to maximize performance, resiliency, and efficiency. The runtime environment leverages a unified stack with performance optimizations across every layer—from metal to model.
CoreWeave Mission Control
Throughout our inference testing, CoreWeave Mission Control™ served as the central dashboard to manage the test environment. We utilized CoreWeave Mission Control's deep observability to monitor every layer of the stack from hardware-level telemetry like GPU temperature and NVLink bandwidth to application-level metrics like time-to-first-token.
To ensure NCCL performance was on target, we utilized a recently launched CoreWeave Mission Control feature, CoreWeave GPU Straggler Detection. This tool provides real-time collective metrics, including Bus Bandwidth, ensuring all GPUs and communication paths perform equally. GPU Straggler Detection also automatically detects any hardware lockups and pinpoints the root cause.
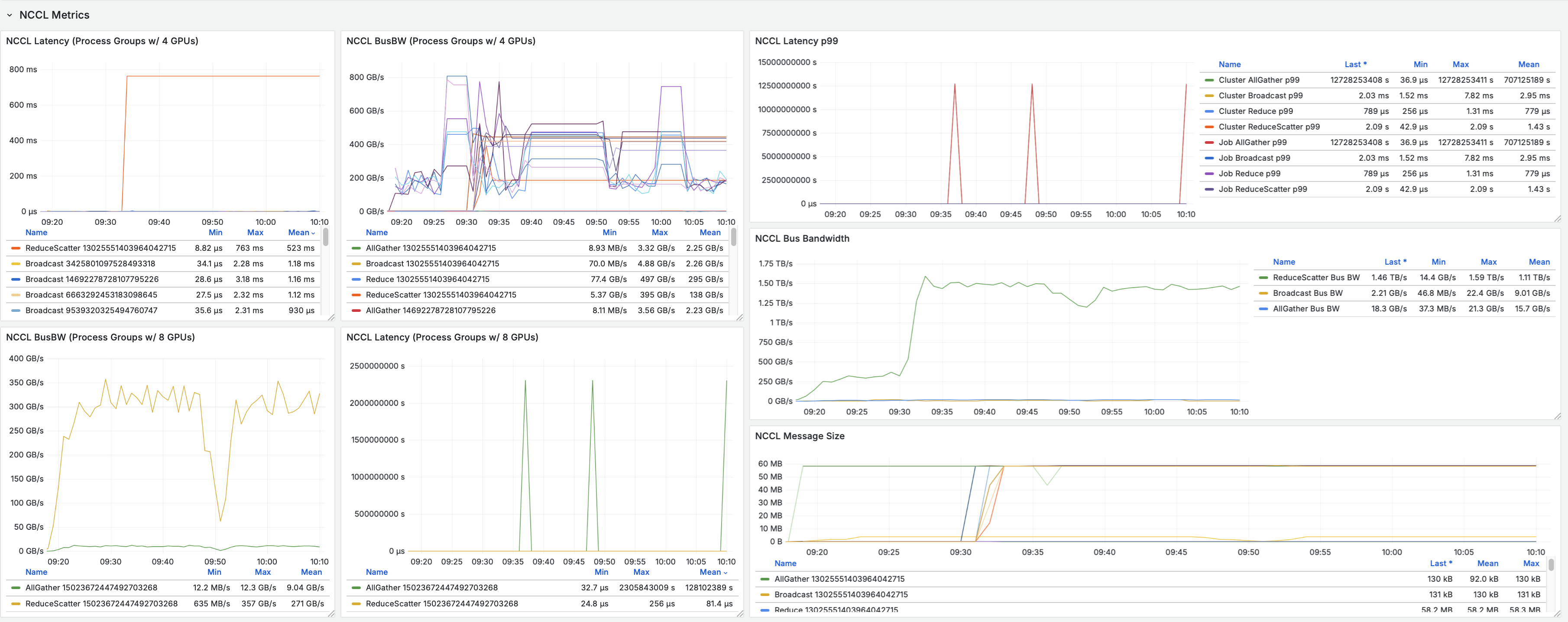
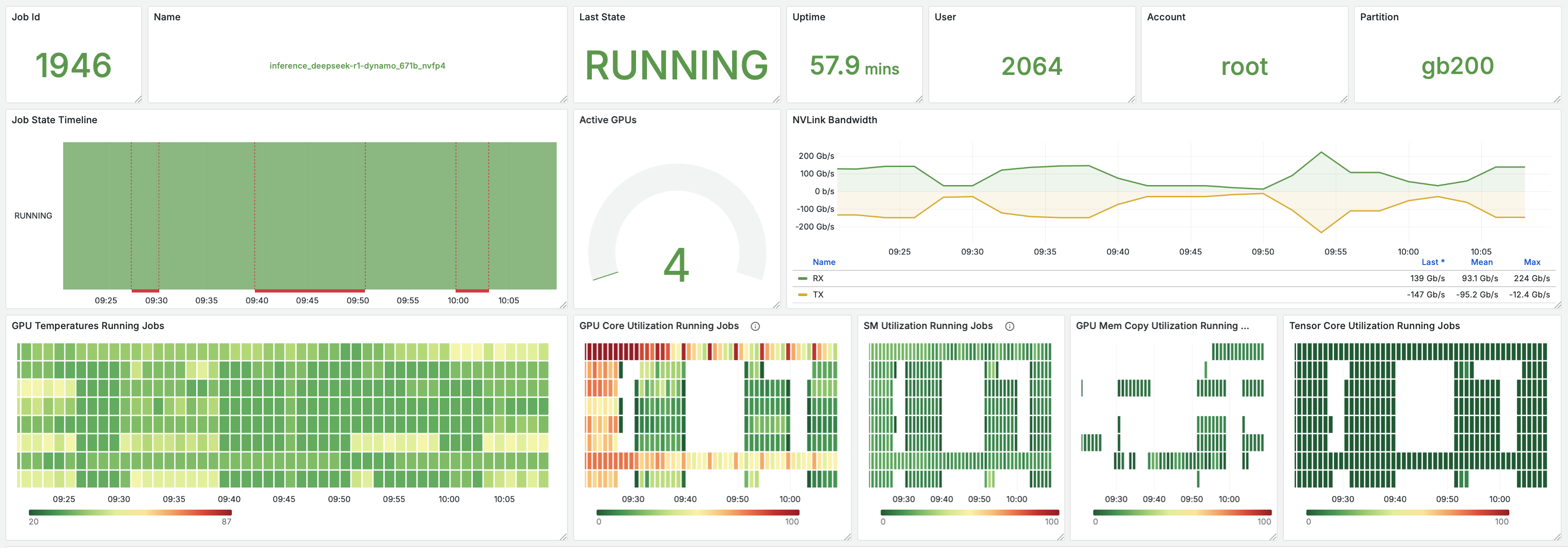
AI-optimized infrastructure
CoreWeave pairs NVIDIA GB200 NVL 72 with high bandwidth networking and optimized memory architectures to eliminate bottlenecks common in generalized cloud environments. This enables sustained high utilization and predictable inference performance at scale.
Optimized model serving for single and multi-node inference
Inference workloads on CoreWeave leverage optimized serving runtimes and scheduling strategies designed to maximize throughput while minimizing latency. Efficient batching, request routing, and GPU utilization are built into the serving stack.
Fast model startup and loading
Production inference depends largely on how quickly models can be brought online. CoreWeave’s high-performance object storage and fast provisioning pipelines significantly reduce model load times, improving time-to-first-token and scaling responsiveness.
Impact of inference performance for production AI systems
CoreWeave’s inference performance builds on the same architectural principles that power its industry-leading training results: purpose-built infrastructure, deep integration across the stack, and a relentless focus on performance under realistic conditions. Becoming an NVIDIA Exemplar Cloud is more than a technical milestone—it is a guarantee of trusted performance, transparency, and reliability, aligned with NVIDIA’s high performance standards, allowing organizations to scale AI with absolute confidence.
For a global retail leader, this might mean deploying agentic customer service bots that can reason through complex returns and supply chain redirects in real-time with expected latency. In financial services, it provides the deterministic performance required for rapid fraud detection and high-frequency risk simulations where every millisecond of time-to-first-token directly impacts the bottom line. By meeting or exceeding the NVIDIA Exemplar Cloud benchmarks for models like DeepSeek-R1 and Llama 3.3, CoreWeave provides validated performance that leading organizations need for everything from running autonomous logistics agents for global shipping to interactive digital twins for industrial manufacturing.
For teams deploying AI applications in production, these performance gains translate directly into operational advantages:
- Faster and more responsive end-user experiences
- Lower cost per inference through higher efficiency
- Improved reliability during traffic spikes
- Predictable performance as workloads scale
CoreWeave delivers the Essential Cloud for AITM
CoreWeave’s commitment to designing a purpose-built AI cloud enables pioneers to uniquely capitalize on the latest GPU architectures. By delivering best-in-class results across both training and inference, CoreWeave provides a unified AI cloud platform capable of supporting the entire AI lifecycle from model development to global production deployment.From large language models to multimodal and real-time inference pipelines, CoreWeave enables production AI systems to operate with confidence at scale.
With CoreWeave Mission Control, the industry’s first operating standard for running AI at production scale, CoreWeave enables efficient fleet operations with full transparency, proven reliability, and deep insights. CoreWeave Cloud enables AI pioneers to deploy their most critical training and inference workloads on a platform verified by NVIDIA to deliver:
- Reduced training and inference time: Groundbreaking performance results that lower the overall time and cost required for training and inference
- Unrivaled reliability: Confidence that long-running jobs will complete without interruption, backed by a rigorously tested architecture
- Performance transparency: The highest level of performance transparency and reproducibility validated by NVIDIA Exemplar Cloud
The most recent Exemplar Cloud results underscore our continued collaboration with NVIDIA, and CoreWeave's ability to maximize efficiency for the most demanding training and inference workloads reinforcing our position as the #1 AI cloud.
Please see additional resources below and join us for a webinar to learn more:
- Join the CoreWeave and NVIDIA Webinar on January 29, 2026: Inside the Rack Scale Revolution: How CoreWeave and NVIDIA Are Building the Foundation for AI’s Next Leap
- Invitation to meet with us at GTC 2026 in San Jose, March 16-19, 2026
- Read our blog: CoreWeave Sets New Standard as First NVIDIA GB200 Exemplar Cloud, Improving Upon NVIDIA’s Own Training Performance Targets

.jpeg)
.jpeg)

.jpg)






