



The question has never been whether your infrastructure will be tested during a long training run. The real question is what happens when it does.
At a small scale (like a test run on 4 to 16 nodes), most systems hold up. But at production scale, the failure profile changes.
Resilience isn’t something you can add later. It’s something you design for from the start. And the difference between infrastructure built for distributed training and infrastructure adapted for it shows up where it matters: utilization, stalled jobs, and recovery time that compounds the original failure.
And in many cases, the root cause isn’t a single component. It’s the architecture itself.
Your reference architecture is working against you
A reference architecture is your structural blueprint. It defines how a system is structured: the components, how they interact, and the properties required to perform reliably under real workloads.
Get that structure wrong, and failures aren’t random. They're structural, they compound, and they get harder to diagnose as scale increases. Meta FAIR's 2024 analysis of large-scale ML research clusters found that at production scale, the majority of training disruptions stemmed from infrastructure-layer issues—not model or software bugs—underscoring how the underlying architecture determines failure frequency and recovery cost.
For distributed AI training, the inherited model of general-purpose infrastructure often looks like this: a coordination layer on top of separate Slurm and Kubernetes clusters, each with its own storage and compute. Data is moved between systems. Metadata is tracked independently. Observability, if it exists, is bolted on at each layer and fragmented across the stack.
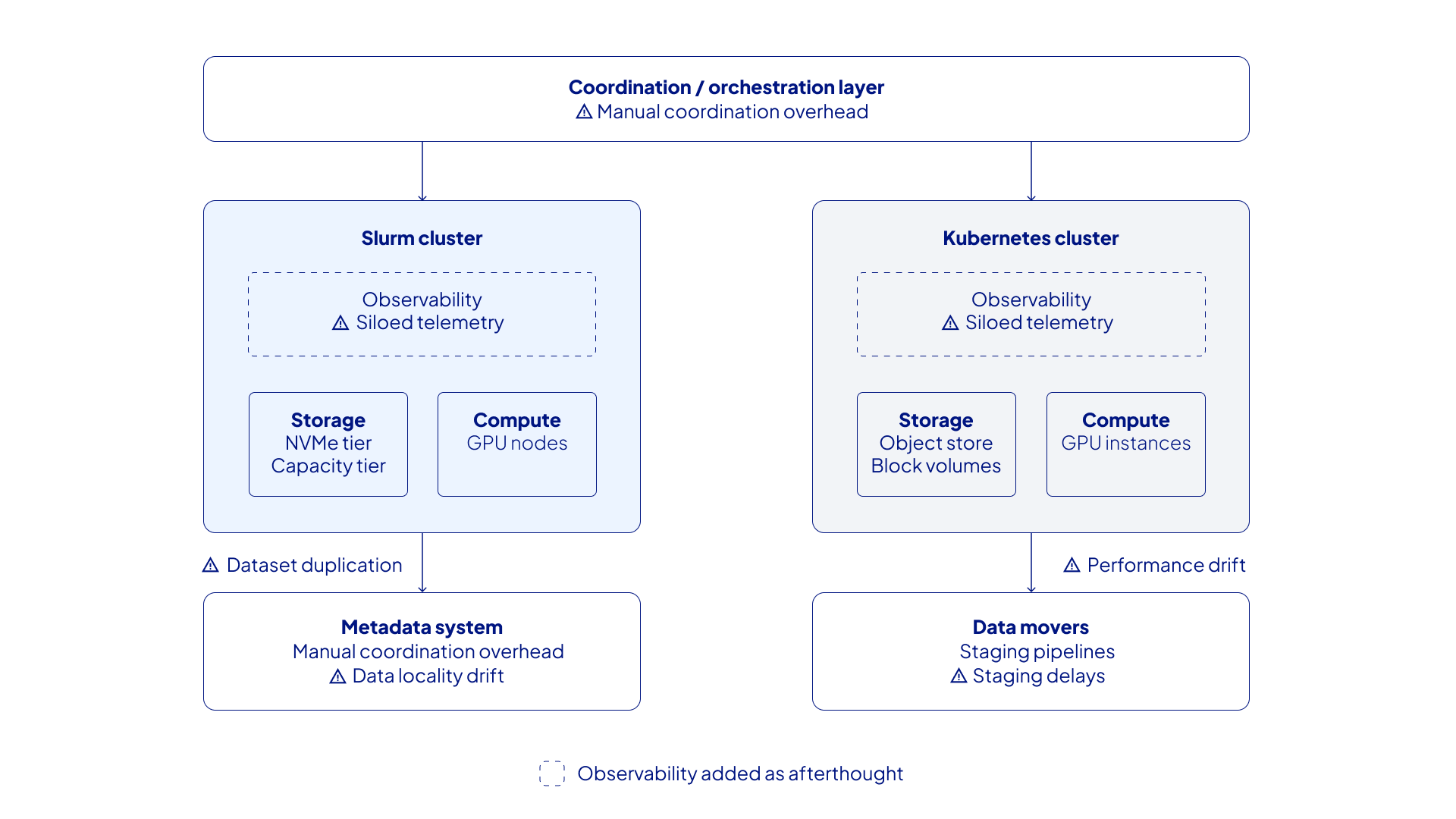
This architecture was built for flexibility—not distributed training. This is the result of bolting components together out of convenience and modularity, and that matters.
General-purpose infrastructure works well when workloads are diverse, loosely coupled, and when high performance is not as critical. Distributed training demands the opposite: homogeneous, tightly synchronized, latency-sensitive, and intolerant to failure.
You may not notice the difference for your 4-node test runs. But when you’re running production workloads on a hundred- to thousand-node cluster, you will. Recurring failure modes like GPU stragglers, hangs, fragile recovery from checkpoints compound, and the system struggles to keep up.
You can add monitoring, tune parameters, and build runbooks. (In fact, your team is probably already doing so.) But you're working against the grain of the system. To truly improve resiliency and make forward progress on your models, you need a reference architecture designed specifically for production-scale, distributed AI training.
The performance difference is measurable: in MLPerf Training v5.0, infrastructure purpose-built for distributed training achieved ~2x faster large-model training across 2,496 GPUs compared to general-purpose alternatives. SemiAnalysis's ClusterMAX evaluation reinforces this—identifying sustained effective throughput and coordination discipline, not peak theoretical capacity, as the factors that actually determine distributed training outcomes at scale.
What purpose-built infrastructure actually looks like, layer by layer
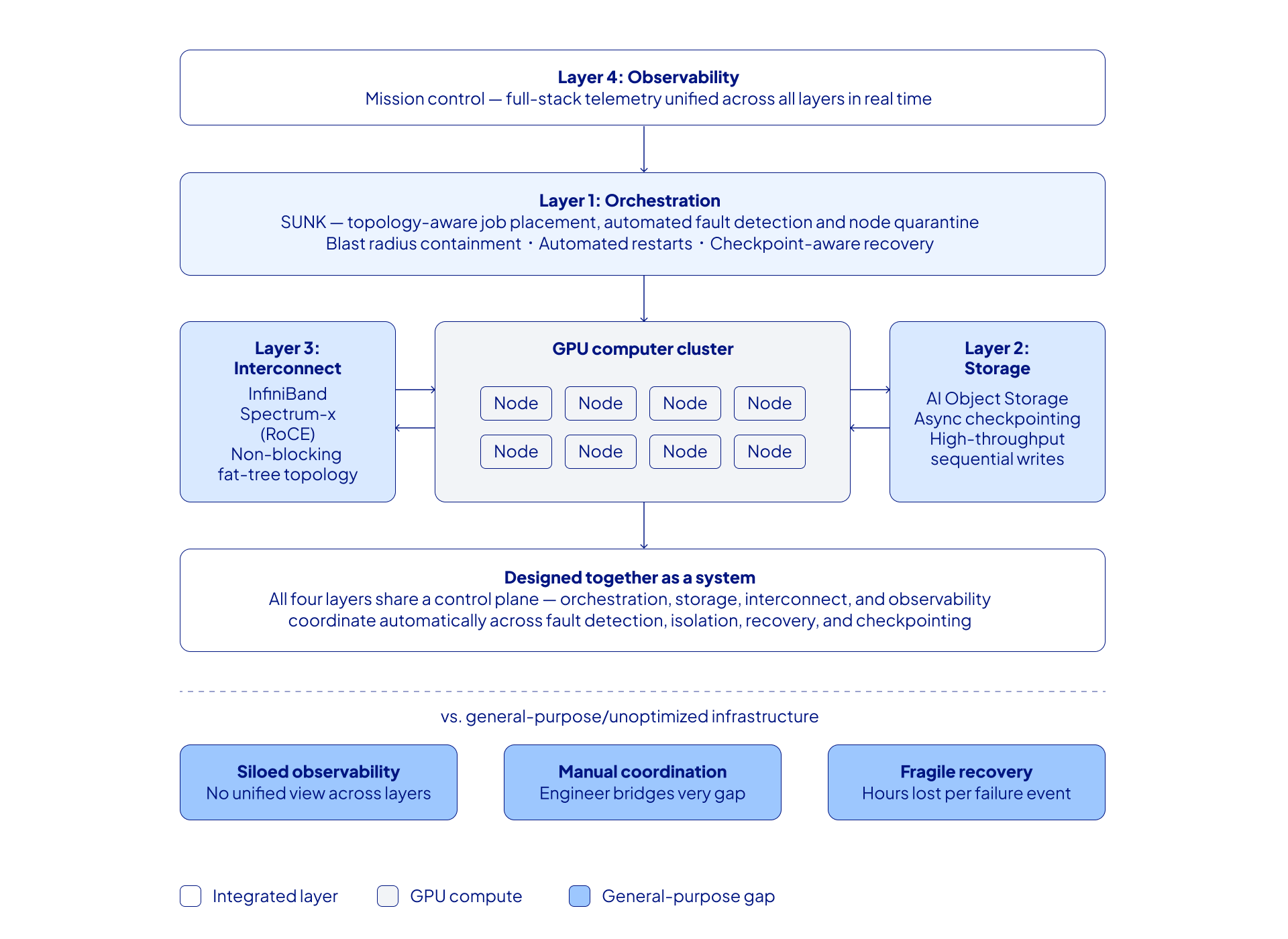
Distributed training reliability isn’t determined by any single component. It’s the result of four interdependent layers, each designed for long-running, large-scale workloads:
- Topology-aware orchestration
- Checkpoint-optimized storage
- High-performance interconnect
- Integrated observability
Each layer addresses a specific failure mode. Together, they determine whether a system holds up under scale. The diagram below shows these layers in the reference architecture of a system designed for production-scale training.
Here’s what each layer does and what breaks when it’s missing.
Layer 1: Topology-aware orchestration
Orchestration determines how jobs are scheduled, placed, and managed across the cluster. In distributed training, placement decisions directly affect communication latency, failure impact, and recovery behavior.
What it enables:
- Topology-aware placement: Keeps tightly coupled processes on hardware that can meet synchronization requirements
- Blast radius containment: Limits the impact of node failures to a subset of the cluster
- Automated fault response: Detects degraded nodes and restarts jobs without manual intervention
- Reproducible environments: Eliminates inconsistencies across restarts
Without topology awareness, coordination overhead grows with cluster size. When this layer is missing, failures spread further, recovery takes longer, and performance becomes unpredictable.
Layer 2: Checkpoint-optimized storage
Checkpointing is what makes failure survivable. But only if storage can keep up.
Distributed training produces large, sequential writes under time pressure. Storage systems optimized for mixed workloads often struggle with this pattern.
What it enables:
- Frequent checkpointing: Reduces recovery loss from hours to minutes
- High-throughput sequential writes: Matches the actual I/O profile of training workloads
- Asynchronous checkpointing: Avoids interrupting training steps
- Consistent recovery state: Ensures restarts resume from valid checkpoints
When storage becomes a bottleneck, teams checkpoint less often. And when failures happen, recovery becomes expensive.
Layer 3: High-performance interconnect
The interconnect determines how efficiently GPUs communicate. Every training step depends on synchronize gradients and model state across the cluster.
What it enables:
- Faster step times: Low-latency communication improves scaling efficiency
- Higher GPU utilization: Reduces idle time during synchronization
- Collective offload: Moves reduction operations into the network fabric
- Consistent bandwidth: Maintains performance under concurrent load
At scale, network performance becomes the limiting factor. General-purpose networks, designed for bursty traffic, degrade under synchronized collective communication. When the network falls behind, GPUs wait. And when GPUs wait, costs rise.
Layer 4: Integrated observability
At scale, visibility isn’t optional. It’s operational infrastructure. Observability needs to span the full stack: hardware, network, storage, and training jobs.
Without it, diagnosis looks like this: an NCCL error surfaces in your logs. You spend hours assuming it's a networking problem, but it turns out to be a degraded NVMe drive on one node causing a straggler, which triggered a timeout in the collective communication operation. You found it eventually—but only after chasing the wrong layer.
This is the dominant failure mode in distributed training environments without integrated observability. Symptoms surface in one layer; root causes live in another. Engineers bridge those gaps manually, and that overhead compounds with cluster size and run duration.
Integrated observability changes the diagnostic model: instead of correlating signals across fragmented tooling, the system surfaces cross-layer relationships automatically—connecting hardware health, network behavior, storage performance, and job execution into a single coherent view.
What it enables:
- Proactive fault detection: Identifies degradation before it becomes failure
- Cross-layer visibility: Connects symptoms to root causes across systems
- Contextual alerts: Links infrastructure events to training performance
- Workflow integration: Fits into existing tooling rather than creating silos
Without this layer, diagnosing failures becomes slow, manual, and incomplete. As a result, your team spends more time tracking down what went wrong before they can begin to resolve the problem.
Four layers. One system.
The four layers above are necessary conditions for distributed training reliability, but they aren't sufficient on their own.
In distributed training, failures don’t stay isolated. A degraded node affects compute, orchestration, storage, and observability at once. Systems that treat these layers independently force engineers to connect the dots manually.
That doesn’t scale.
A resilient architecture defines how layers interact under load, how they respond to failure, and how visibility is maintained across the system.
Infrastructure that wasn't built to handle that interaction makes failures harder to diagnose and more expensive to recover from. Before committing to an architecture, these are the questions that matter:
- When a node degrades or falls behind, what happens across the stack and in what order? Is there a defined handoff between observability and orchestration, or does the engineer connect those dots manually?
- Is there a control plane coordinating behavior across layers, or do components interact only at the workload level?
- How is cluster health surfaced to the engineer, and at what granularity? Can you see a straggler forming before it stalls a training step?
- What is automated, and what requires manual intervention? Where does the handoff happen, and is it defined?
If those answers aren’t clear, the coordination work falls to your team. That overhead scales with cluster size and run duration—exactly when you can least afford it.
What that blueprint looks like in practice
The four layers define the structural blueprint. What determines success in production is whether they were designed together for the same workload.
CoreWeave's architecture maps directly to this blueprint:
- Orchestration: SUNK (Slurm on Kubernetes)
- Storage: CoreWeave AI Object Storage
- Interconnect: high-performance connectivity made for AI, including NVIDIA Quantum InfiniBand and Spectrum-X (RoCE)
- Observability: CoreWeave Mission Control
These are not features added to a general-purpose platform. They are purpose-built to integrate with each other to create an AI-specific system. And that distinction shows up under real workloads.
What’s next
This post outlines the architecture. The next piece goes deeper: a technical guide your team can use to evaluate and benchmark your current environment.
Check out these related assets for more information:
- Check your infrastructure's readiness: Can Your Infrastructure Take the Punch?
- Go deeper on full-stack observability: CoreWeave Mission Control, the new operating standard for observable AI infrastructure


.avif)








