Comprehensive hardware dashboards
Visualize your entire fleet of NVIDIA GPUs in one place, complete with details about every node.
SUNK integration
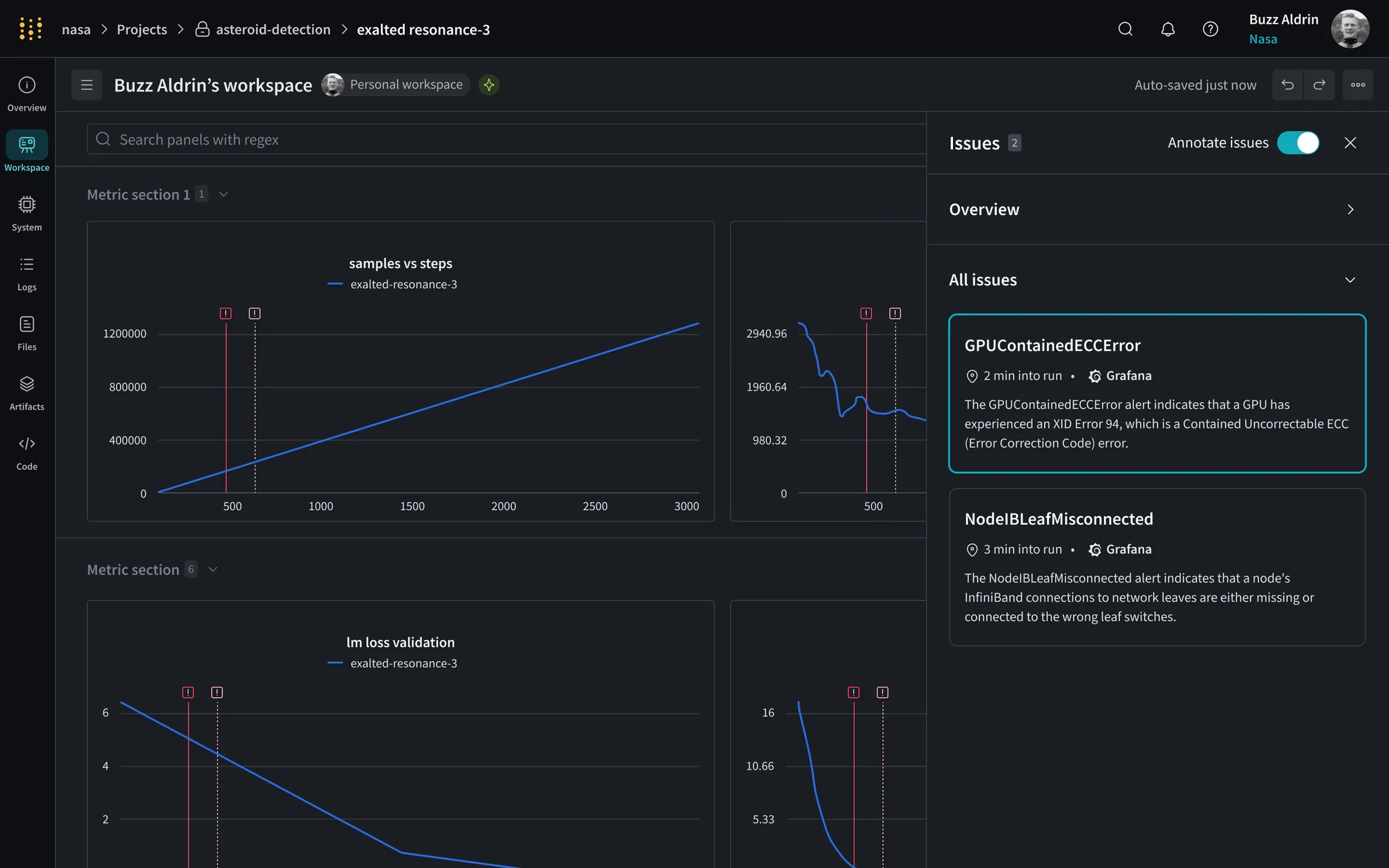
Overlay telemetry from hardware, Kubernetes, and Slurm jobs to quickly identify problem areas.
Cluster health management
Instead of worrying about infrastructure, offload GPU cluster health management to CoreWeave so that you can focus on shipping cutting-edge AI applications.
Network backbone visibility
See real-time ingress and egress traffic throughput from each node in your cluster to external Internet endpoints such as external model weight data sources to identify under-optimized workloads.
Easy visualization
CoreWeave makes it easy to correlate training job interruptions all the way down to a networking or infrastructure problem. Optimize your workloads to take full advantage of CoreWeave’s blazing-fast Kubernetes-on-bare-metal.