


Machine learning (ML) is a subset of artificial intelligence (AI) that enables systems to learn from data and improve their performance over time through experience, without explicitly programming.
Instead of relying on hardcoded rules, ML models identify patterns in large datasets and use those insights to make predictions, classify information, or guide decisions. This data-driven approach underpins many modern AI applications, from personalized recommendations and search engines to generative tools and self-driving vehicles.
In this guide, you'll learn what machine learning is, how it works, the different types of ML, and the real-world problems it solves. We'll also explore common algorithms, technical challenges, and frequently asked questions to help you understand where machine learning fits into today’s AI ecosystem.
How does machine learning work?
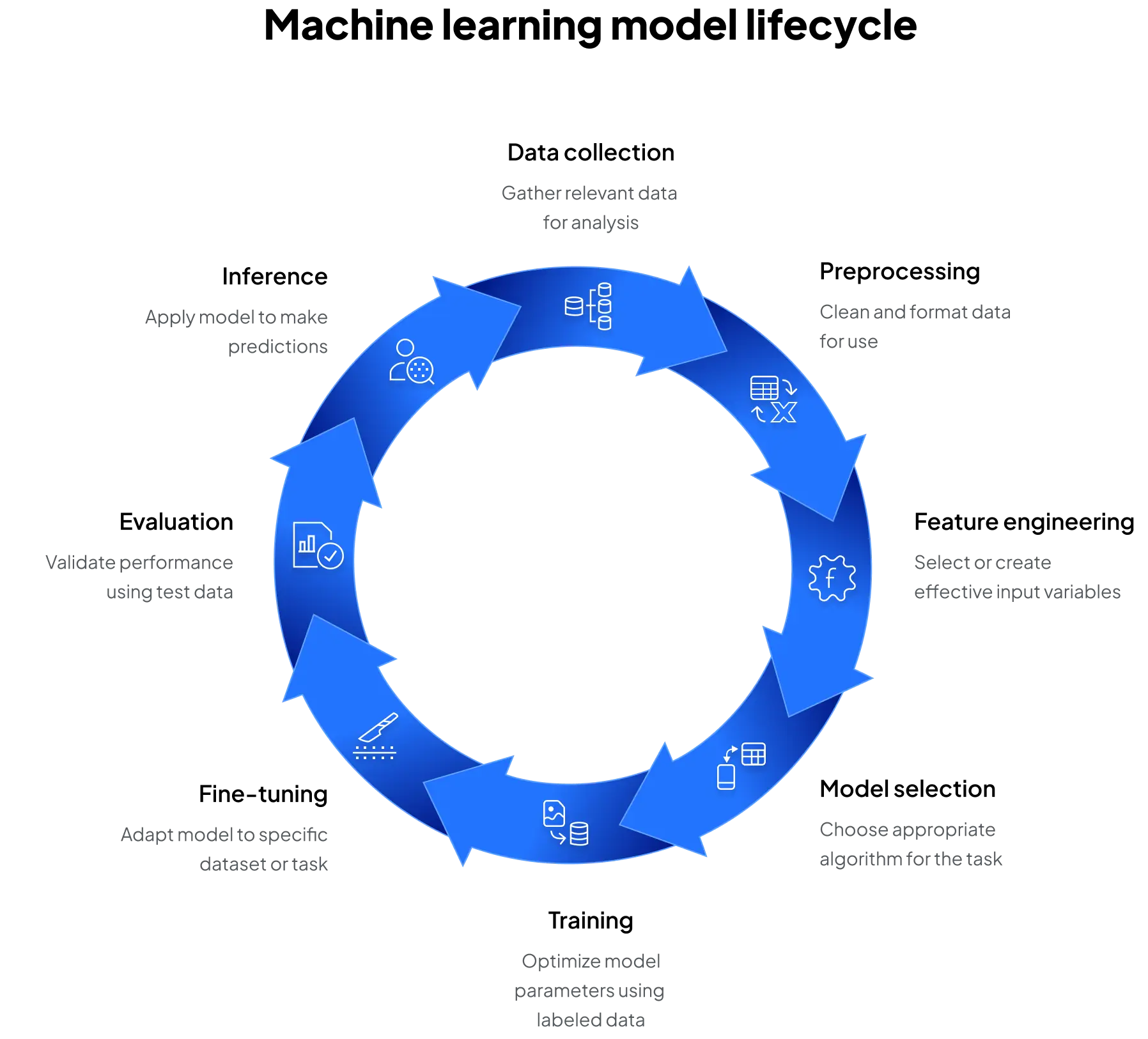
Machine learning models follow a structured lifecycle that allows them to generalize from data:
- Data collection: assemble relevant data (structured or unstructured)
- Preprocessing: clean and format the data for analysis and modeling
- Feature engineering: select or create input variables that help the model learn effectively
- Model selection: choose an algorithm based on the problem type
- Training: optimize model parameters by minimizing error on labeled data
- Fine-tuning: adapt a pre-trained model to a specific dataset or task, which reduces compute needs and improves task-specific accuracy
- Evaluation: validate performance using test data and key metrics
- Inference: apply the trained model to make predictions on new, unseen data
This process doesn’t end with inference; it operates as a continuous cycle. Real-world conditions, new data, and shifting objectives often require models to be retrained, fine-tuned, or updated with fresh features. Continuous monitoring and iteration ensure that ML systems stay accurate, reliable, and relevant over time.
ML workflows usually rely on accelerators like GPUs to efficiently process high-dimensional datasets during both training and inference stages.
Types of machine learning
Not all machine learning problems are alike. The type of data available, the task you want to solve, and the amount of human input you can provide all influence which learning approach is best. For example, some models learn directly from labeled examples, while others must uncover hidden patterns without guidance. In certain cases, models even learn by interacting with an environment and receiving feedback on their actions.
Machine learning approaches can be categorized into three primary types:
In addition to these core categories, hybrid approaches are gaining traction:
- Semi-supervised learning combines small amounts of labeled data with large unlabeled datasets to improve model performance when labels are expensive or hard to obtain
- Self-supervised learning has emerged as a powerful method in natural language processing and generative AI, where models generate their own training signals from raw data (e.g., predicting missing words in a sentence)
Each approach addresses different problem types, with supervised learning being the most commonly used in applied AI today. However, unsupervised and reinforcement methods are increasingly critical for complex, dynamic, and data-scarce environments.
Common ML algorithms
At the core of every machine learning model is an algorithm: a set of mathematical rules or procedures the model uses to detect patterns in data. During training, the algorithm guides the model's parameter updates to minimize error and improve performance. Different algorithms are better suited for different kinds of data, tasks, and performance requirements, which is why a wide range of options exists.
Here are four major categories of algorithms commonly used in machine learning:
Within those main categories, Machine learning offers a wide range of algorithms to address specific tasks:
- Linear regression: predicts continuous numeric outcomes
- Logistic regression: used for binary classification
- Decision trees and random forests: tree-based models that handle classification and regression
- Support vector machines (SVM): classifiers that separate data using optimal boundaries
- Naive bayes: probabilistic models often used in text classification
- K-means clustering: groups data into clusters without labels
- Neural networks: layered models that power deep learning applications such as language models and image recognition
The choice of algorithm depends on the nature of the data, task complexity, interpretability requirements, and compute resources available. For example, decision trees may be easier to explain to stakeholders, while deep neural networks can achieve higher accuracy but require specialized hardware, such as GPUs, to train efficiently.
Real-world ML use cases
Machine learning drives a broad spectrum of real-world applications across industries. These systems depend on ML models that can adapt to data trends, scale efficiently, and deliver insights in real-time.
Healthcare
Across the healthcare ecosystem, ML models support predictive diagnostics, medical image analysis, and personalized treatment recommendations. Hospitals use ML to optimize resource allocation and patient flow, while insurers apply it for risk assessment and cost prediction. Researchers also leverage ML to accelerate drug discovery and genomic analysis, advancing precision medicine.
Finance
Banks and fintech companies use ML for credit scoring by analyzing thousands of customer data points to assess risk more accurately. Fraud detection systems flag unusual transactions in real time, preventing billions in losses. Algorithmic trading platforms also leverage ML to analyze market signals and execute trades faster than human decision-making allows.
Retail and e-commerce
Recommendation engines suggest products based on a customer’s browsing and purchase history, driving higher sales and engagement. ML also supports customer segmentation, enabling targeted marketing campaigns that improve conversion rates. Dynamic pricing algorithms adjust costs based on demand, competition, and inventory levels to maximize profitability.
Transportation
Autonomous driving systems rely heavily on ML for tasks such as object detection, lane tracking, and decision-making under uncertainty. Ride-hailing and logistics companies use ML for demand forecasting to position vehicles where they’re needed most. Route optimization models also reduce fuel use and improve delivery times.
Media and entertainment
Streaming platforms use ML to personalize content delivery, suggesting movies, music, or games based on past behavior. Real-time translation and voice synthesis powered by ML allow global audiences to enjoy content in their preferred language. Generative models are also enabling new forms of digital storytelling and interactive media experiences.
Cybersecurity
ML systems monitor massive volumes of network traffic to detect anomalies that signal potential cyberattacks. Malware classification models quickly identify and contain new threats, even when signatures are unknown. Threat modeling tools also help organizations anticipate vulnerabilities and strengthen their defenses proactively.
Robotics and autonomous systems
From industrial robots on factory floors to drones and household assistants, ML enables machines to perceive their environment and make autonomous decisions. Reinforcement learning and computer vision enable tasks such as object manipulation, navigation, and human–robot collaboration. These advances improve efficiency, safety, and adaptability across industries ranging from manufacturing to agriculture.
Challenges in machine learning
Despite its capabilities, machine learning presents a unique set of challenges:
- Data quality and bias: poor or unrepresentative data leads to inaccurate or unfair models
- Model interpretability: complex models, especially deep learning ,can be hard to explain and audit
- Compute resource constraints: training large models often requires high-performance GPUs and significant memory bandwidth
- Model drift: over time, real-world data may diverge from training data, degrading performance unless retrained regularly
- Ethical and regulatory concerns: responsible AI practices are needed to ensure fairness, transparency, and compliance
These challenges directly impact teams trying to build and execute an AI roadmap—whether the focus is on training new models, fine-tuning existing ones, or scaling inference in production. Left unaddressed, they can delay projects, increase costs, and reduce trust in AI systems.
Organizations must address these limitations proactively to scale ML systems effectively and responsibly. To overcome them, organizations are increasingly turning to strategies such as better data governance, explainable AI tools, cloud-based GPU resources, and continuous monitoring pipelines that keep models accurate and aligned with business goals.



