



As models scale to trillions of parameters—and pipelines become more distributed—AI pioneers are quickly moving toward high-performance, cross-cloud architectures. This enables them to efficiently leverage compute and storage resources everywhere. To maximize the impact and improve ROI of these valuable resources, today’s platform engineers are increasingly designing for cross-cloud training and inference. This flexibility allows them to balance performance, reliability, cost, and geographic flexibility to more rapidly deploy AI workloads.
In the AI era, different requirements govern these cross-cloud architectures. Many organizations originally deployed multi-cloud for resiliency. Now teams are seeking speed, agility, and throughput to maximize the impact of their accelerated platforms. That’s why today, we are announcing CoreWeave Interconnect, SUNK Anywhere and LOTA Cross-Cloud, as three critical capabilities that make cross-cloud AI easier and more accessible whether by network, storage, or compute. We also have new integrations between the Weights & Biases tools and Google Cloud. Customers like Noble Machines, and PathAI are using Weights & Biases tools on Google Cloud to accelerate AI workflows. With new integrations between the Weights & Biases tools and Google Cloud, customers can observe agents and continuously improve their reliability.
Revolutionizing cloud interconnect for the AI era
Building cross-cloud infrastructure remains complex, time-consuming, and costly. Traditional approaches involve extensive planning and provisioning, expensive networking infrastructure, and intricate routing and security configurations. As training and inference workloads become increasingly distributed across different clouds, infrastructure engineers are looking for faster, more efficient ways to connect and operate these environments.
For example, connecting two clouds typically requires organizations to rely on third-party providers, as shown in Figure 1. This results in operating across three separate environments, with added complexity from circuit provisioning, routing policies, security validation, performance testing, and observability. It also introduces additional contracts to manage and negotiate.
These deployments often take months to complete, typically increase network latency, and create new points of failure. They may also lack capabilities such as link-layer encryption and require ongoing upgrades, ultimately driving up total cost of ownership.

To address these challenges, we’re collaborating with Google Cloud to launch CoreWeave Interconnect, a private high-performance fiber-based network interconnect that directly connects CoreWeave Cloud to Google Cloud—without the complexity of managing additional equipment and providers. CoreWeave Interconnect minimizes latency, helps ensure maximum reliability, and delivers built-in security through MACsec encryption at line rate. Available in private preview soon, CoreWeave Interconnect will be available in select regions, giving customers the flexibility to select the bandwidth they need.
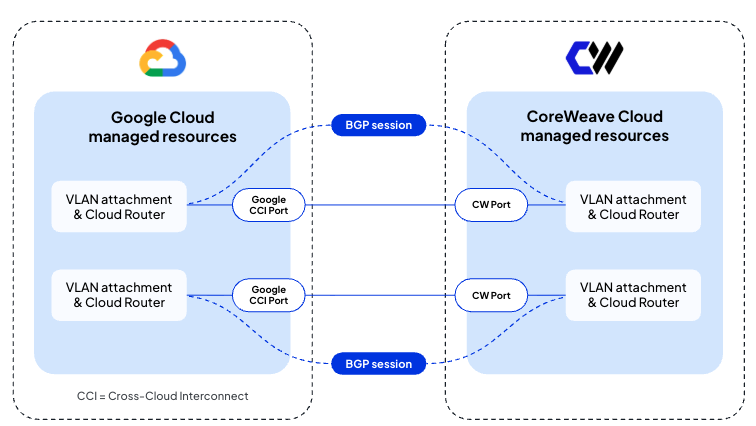
"Collaborating with Google Cloud extends the reach of CoreWeave's AI-native platform through Google's global network," said Chen Goldberg, EVP of Product and Engineering at CoreWeave. "CoreWeave Interconnect introduces a solution to a problem that has prevented organizations from reaching across clouds to leverage AI resources. By removing the friction of cross-cloud, we are making it simpler and faster for organizations to run workloads anywhere.”
CoreWeave Interconnect leverages Google Cloud’s Partner Cross-Cloud Interconnect to create a unified cross-cloud network fabric, empowering developers to run their training and inference workloads wherever they are needed.
“Google’s Cross-Cloud Network removes cloud boundaries, making it easier to build distributed, AI-powered services,” says Rob Enns, VP/GM of Cloud Networking at Google Cloud. “Collaborating with CoreWeave and using our Partner Cross-Cloud Interconnect gives customers the secure, low-latency connectivity needed to simplify complex cross-cloud workloads and accelerate AI outcomes.”
With a global footprint of 44 data centers worldwide, CoreWeave Cloud is built with an extensive private, carrier-grade network backbone secured with MACsec encryption over terrestrial and subsea fiber optic cabling. By unifying an IP and optical network to connect CoreWeave data centers, we offer extensive 400Gbps to terabits of capacity over our backbone network.

CoreWeave’s connectivity offerings gives infrastructure engineers the ability to simplify cloud networking and build a cross-cloud network fabric designed to accelerate their training and inference deployments everywhere. Organizations benefit from CoreWeave’s high-performance, high-capacity network backbone. And with no data transfer fees across our network or at egress, customers avoid unexpected costs and budget overruns that can otherwise limit innovation.
Simplifying cross-cloud training with SUNK Anywhere
Cross-cloud AI training creates new capacity and flexibility, but it also potentially introduces fragmentation unless teams carry the same training system across environments. SUNK Anywhere extends CoreWeave’s unified training system to support GPU environments across clouds or on-premises, giving teams a more consistent way to scale beyond a single deployment.
CoreWeave’s SUNK combines the agility and scale of Kubernetes with the orchestration power of Slurm, and has been a powerful tool available on CoreWeave infrastructure. Now, platform and research teams can add capacity anywhere, including Google Cloud, AWS, or Azure without rebuilding the workflows and operational model they already use on CoreWeave. Built to support demanding, long-running training jobs at massive scale, SUNK Anywhere helps simplify cross-cloud GPU training while preserving the consistency teams need to keep work moving forward.
CoreWeave's SUNK is hands-down industry best cluster management. It's slurm on kubernetes and gives us the best of both. We love using it. Frictionless interop between them. It's very impressive how many edge cases have been well handled. Our research scientists love using slurm as their job orchestrator and kubernetes gives us the observability and production-grade long-lived services that our products need. We're running large distributed jobs across thousands of GPUs on both CoreWeave and non-CoreWeave providers and deploying SUNK on our non-CoreWeave clusters requires very few configuration changes.
Xander Dunn, Member of Technical Staff, Periodic Labs
SUNK, simplifies cross-cloud AI training by creating a unified control plane for scheduling, scaling, and running distributed workloads across environments. Traditionally, organizations have had to manage separate schedulers, fragmented infrastructure, and complex networking when training models across multiple clouds or hybrid setups. SUNK enables teams to run HPC-style workloads alongside cloud-native services, eliminating silos while preserving the performance, job control, and queuing capabilities that AI and research teams rely on.

Run anywhere, optimize everywhere
SUNK is especially valuable for common use cases such as large scale model training that bursts across multiple regions, hybrid workflows that span on-prem clusters and cloud GPUs, and multi-tenant environments where different teams share infrastructure, but require strict workload isolation and prioritization. It also supports iterative experimentation, where researchers need to quickly spin up, pause, and scale distributed jobs without reconfiguring infrastructure. With Slurm orchestrating jobs and Kubernetes handling containerized environments, users can seamlessly move workloads between clusters or clouds while maintaining consistency in tooling and workflows.
SUNK Anywhere builds on this foundation by offering a high-performance, GPU-optimized platform with integrated networking and storage, designed specifically for AI workloads. Its managed Slurm on Kubernetes environment abstracts away operational complexity, automates provisioning, and provides deep visibility into job performance and resource utilization. Combined with private, high-speed interconnects for cross-cloud data transfer, CoreWeave enables secure, low-latency training across environments. This allows pioneers to scale efficiently, reduce operational overhead, and accelerate time to insight without compromising on control or performance.
Achieving data flexibility with LOTA™ Cross-Cloud
A training job is only as strong as the data it can reach. CoreWeave AI Object Storage is uniquely built to accelerate data access using CoreWeaves’s patented Local Object Transport Accelerator (LOTA) technology to place data directly onto GPU nodes. By bringing data closer to compute, CoreWeave AI Object Storage delivers near-local throughput of up to 7 GB/s per GPU.
CoreWeave’s experience supporting some of the most demanding AI workloads on the planet has made one thing clear: Universal data access for AI workloads gives companies the agility to stay ahead in a fast-moving industry. LOTA Cross-Cloud enables AI builders to store their data in one place and run their workloads anywhere.
LOTA Cross-Cloud, now in limited availability for workloads on Google Cloud and other providers, extends CoreWeave’s patented AI caching technology beyond a single environment. It gives teams consistent, high-throughput data access across regions and clouds, without forcing them into a specific infrastructure footprint. Teams working across clouds can run faster, more efficient training jobs, with fewer bottlenecks between storage and compute, all without paying for transactions or egress.
CoreWeave's LOTA cache enables us to seamlessly access our massive datasets stored in CoreWeave AI Object Storage to power training workloads on our clusters across clouds. LOTA eliminates burdensome data replication and egress fees while giving us near-local throughput, ensuring our compute resources remain fully utilized across our multi-cloud environment.
Cecile Robert-Michon, Director of Internal Infrastructure at Cohere
For teams ready to move data closer to high-performance infrastructure, CoreWeave’s Zero Egress Migration ([0]EM) program simplifies the process. Customers can move large-scale datasets from major cloud providers directly to CoreWeave through a secure, white-glove service with CoreWeave covering the egress fees when leaving their existing cloud. Once data is in CoreWeave AI Object Storage, customers will not pay CoreWeave egress fees, regardless of where that data is used and can leverage LOTA Cross-Cloud to get local data throughput anywhere the job needs to run.
Together, [0]EM and LOTA Cross-Cloud create a more efficient data ecosystem that is faster to operate and more cost-effective at scale. SUNK and LOTA will both soon be available on Google Cloud Marketplace. Current customers can request access to LOTA Cross-Cloud by reaching out to their respective technical solutions manager.
AI developer tools that work across clouds
Customers already rely on Weights & Biases to work seamlessly with their cloud platform of choice, and we’re continuing to expand our integrations. As the pace of innovation across the AI ecosystem accelerates, this matters more than ever. Developers need the flexibility to choose the tools and platforms that best fit their workflows.
"At Pickle Robot, we build autonomous robots that handle the most physically demanding jobs in warehouse logistics, starting with trailer unloading," says Ari Eisenstein, CTO of Pickle Robot Company. "Weights & Biases lets our ML engineers track experiments end-to-end, manage large-scale training runs, and iterate quickly on novel approaches. Running it on Google Cloud means our team can draw on data sets built up over many hours of real fleet operation, and it works naturally with our existing infrastructure." With new integrations between the Weights & Biases tools and Google Cloud, customers can observe agents and continuously improve their reliability.
Therefore, we are excited to share that Weights & Biases now offers native integration with Gemini CLI, Google's open-source agentic AI toolkit. Through a W&B MCP extension for Gemini CLI, developers can ground code changes in live W&B runs, evaluations, and production traces, and automatically generate shareable W&B analysis reports—all without leaving their CLI workflow. Under the hood, W&B Weave captured traces can automatically be used by the Google GenAI SDK and Vertex AI API and Gemini CLI via the Weights and Bias MCP server.
Also new, Gemma 4 31B-int is available on W&B Inference. W&B Inference provides frictionless access to leading open-weight models. Using just a W&B API key, developers can call inference and pay-per-token on a large range of leading OSS models. Customers use this model for advanced reasoning, code generation, vision, and longer context to help developers power a large variety of agentic workloads.
Finally, Weights & Biases now provides comprehensive, native system metrics tracking for Google Cloud TPUs. Previously limited to basic HBM usage and duty cycle, the W&B SDK now automatically collects the full spectrum of TPU performance metrics—including Tensor Core utilization—which is unavailable through Google's standard gRPC monitoring service and was only made possible by integrating directly with the libtpu runtime SDK via FFI. This is potentially the single most important metric for understanding whether your TPU workload is compute-bound.The expanded set of tracked metrics covers the entire TPU performance stack, including:
- Compute: Tensor Core utilization, duty cycle
- Memory: HBM total capacity, HBM usage
- High Level Operation execution: HLO execution timing distributions, HLO queue depth
- Collective communication and transfer latency distributions: collective end-to-end latency, round trip latency at transport layer, throughput at transport layer
The W&B SDK will automatically collect everything available, reading from the libtpu SDK directly with a fallback to the gRPC runtime service.
CoreWeave Cloud: Maximize performance and efficiency
As AI workloads scale in size and complexity, the ability to operate seamlessly across clouds is no longer optional, it’s foundational. By simplifying connectivity, unifying training workflows, and enabling high-performance data access anywhere, CoreWeave and Google Cloud are removing the barriers that have historically limited cross-cloud AI.
Together, these innovations empower organizations to run training and inference wherever it makes the most sense—maximizing performance, improving efficiency, and maintaining control over cost and data. The result is a more flexible, scalable, and economically efficient approach to AI infrastructure, built for the demands of the next generation of AI.
Learn more about CoreWeave
- Learn more about CoreWeave Cloud Networking services
- Inside the Rack Scale Revolution: How CoreWeave and NVIDIA Are Building the Foundation for AI’s Next Leap
- Sign up to learn about CoreWeave Fully Connected 2026
- Current customers can request access to LOTA™ Cross-Cloud by reaching out to us here.


.avif)








