



AI leaders are making strategic infrastructure decisions everyday that shape both cost structure and competitive advantage. As organizations move from AI experimentation to production-scale, the financial implications of infrastructure choices become material, often spanning hundreds of millions of dollars over multi-year horizons.
Yet despite this shift, many cloud evaluations still rely on a familiar but incomplete metric: cost per GPU hour.
While GPU pricing is easy to compare, it does not reflect the realities of operating large-scale AI systems. AI workloads are not isolated compute problems; they are tightly coupled systems where compute, storage, networking, and orchestration must work together efficiently. When evaluated holistically, the differences between platforms become significant.
A recent three-year total cost of ownership (TCO) analysis by Signal65 found that architectural and efficiency differences can drive a 47% to 54% variance in TCO between providers. For production-scale deployments, that gap is not incremental; It’s transformational.
Here are the five key factors that platform leaders should prioritize when calculating the true cost of an AI cloud.
1. Evaluate the full stack, not isolated resources
In production environments, GPUs represent one component of the overall system. High performance storage, often at petabyte scale, is required to sustain throughput. Networking must support distributed workloads across regions requiring interconnects and data transfer fees.
Software layers determine orchestration across multiple, concurrent workloads. Orchestration layers such as Kubernetes are necessary to manage resources efficiently. However, support varied widely among hyperscalers. While CoreWeave does not charge for CKS (CoreWeave Kubernetes Service), the Signal65 TCO study showed that some hyperscalers support a Kubernetes version for only 14 months under standard contract, forcing customers to buy expensive extended support for the next 12 months and beyond before reaching end of life.
These elements are not optional, they are integral to running AI at scale with the required performance, and choices drive recurring costs over time. In many cases, storage alone can account for up to a third of total cost, making it a critical factor in any TCO analysis.
The AI implication: Optimizing a single line item does not optimize the system. TCO must be evaluated at the full stack, platform level, not the component level.
2. Translate GPU efficiency into economic efficiency
GPU efficiency translates directly into cost and ultimately determines the economic value of compute. At enterprise scale and in production use cases, the question is not how much GPU capacity is provisioned, but how much of that capacity is effectively utilized. Metrics such as Model FLOPs Utilization (MFU) and Goodput provide a more accurate view of real-world performance by measuring how much compute is actually used for productive work.
Even relatively modest improvements in these metrics compound significantly when applied across thousands of GPUs. For example, the Signal 65 report found increasing MFU from industry averages in the low 40% range to closer to 50%, combined with improvements in goodput from roughly 90% to 96%, can translate into approximately 25% more effective compute output.
When normalized against cost, this results in up to 96% more TFLOPs per dollar. In practice, this means that two environments with identical GPUs can deliver dramatically different economic outcomes depending on how efficiently those GPUs are utilized.
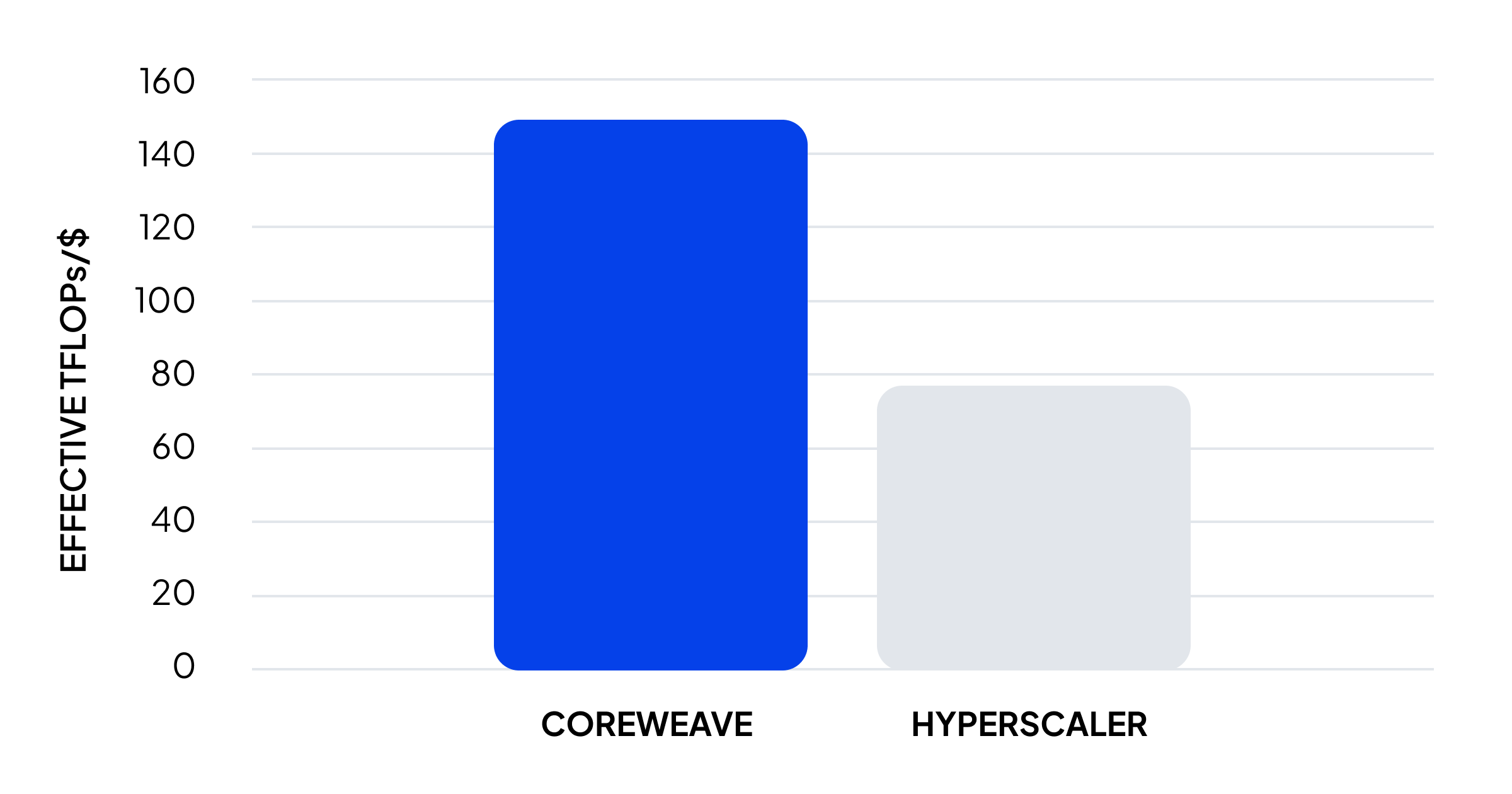
The AI implication: Cost efficiency is not determined by the price of compute. It is determined by the amount of useful compute delivered per dollar.
3. Align storage architecture with GPU throughput requirements
Storage architecture is another critical, and often underestimated, driver of both performance and cost. In AI systems, storage is not just a passive repository of data, it has a direct impact on overall compute efficiency. Training and inference workloads require sustained high throughput data access, massive parallel read and write operations, and efficient handling of mechanisms such as checkpointing and KV-cache offload.
Traditional cloud architectures frequently require combining multiple storage tiers to meet these demands, such as object storage and high performance parallel file systems. This approach introduces both complexity and cost, often forcing organizations to overprovision storage capacity simply to achieve the necessary performance characteristics. The result is idle GPU time, wasted spend, and inflated infrastructure costs.
By contrast, architectures designed specifically for AI can deliver high performance directly from object storage layers, reducing the need for separate tiers and lowering overall storage costs by as much as 62%.
“The elimination of API request and data egress fees is a significant differentiator for CoreWeave. At petabyte scale, these charges can amount to millions of dollars over three years. Beyond the raw costs, the greater challenge is their unpredictability – introducing ongoing complexity in cost forecasting. By removing these fees entirely, CoreWeave delivers not only lower total storage costs but also a simpler, more transparent pricing model without hidden variables.”
Signal 65
The AI implication: Storage design is not a secondary consideration. It is a primary determinant of both utilization and total cost.
4. Prioritize cost transparency and predictability to enhance planning cycles
One of the most challenging tasks AI leaders face is planning ahead when they are juggling multiple teams, workloads, projects, etc. This is where cost transparency and predictability are key. At production scale, financial planning requires a high degree of confidence in how costs will evolve over time. Many cloud pricing models introduce variability through mechanisms such as:
- Data transfer or egress fees
- API request charges
- Observability and logging costs
- Support fees tied to total spend
These costs are often difficult to model accurately upfront and tend to increase with usage in non-linear ways taking teams by surprise. As AI workloads grow in size and complexity, these unpredictable and variable costs can become a significant portion of the total bill, often exceeding initial expectations to become bill shock for many. In contrast, more transparent pricing models that eliminate or bundle these components provide greater predictability and reduce financial risk. For organizations operating in regulated or cost-sensitive environments, this planning certainty is not simply a convenience. It is a requirement.
The AI implication: A cloud that is difficult to model financially introduces risk, particularly in regulated, cost-sensitive environments.
5. Choose architectures purpose-built for AI workloads
Finally, leaders must consider whether the underlying infrastructure is purpose-built for AI workloads. There is a fundamental difference between general-purpose cloud platforms and those designed specifically for AI.
General-purpose clouds are optimized for flexibility, supporting a wide range of enterprise applications. While they offer GPU-based services, these are often layered onto architectures that were not originally designed for high-density, high-throughput AI workloads. This can result in fragmented systems, additional configuration overhead, and lower overall efficiency that translates into higher costs.
In contrast, AI-optimized clouds are designed from the ground up to support GPU-intensive workloads, with integrated compute, storage, and networking that work together as a cohesive system. This alignment reduces complexity, improves utilization, and ultimately lowers total cost.
The impact is measurable, with AI-optimized platforms demonstrating up to 44 to 47% lower total cost over three years in large-scale deployments.
The AI implication: Alignment with workload type is a primary determinant of long-term efficiency.
Next steps for AI pioneers
Signal65’s research shows that AI infrastructure cannot be evaluated using the same criteria as traditional cloud workloads. The relevant metric is no longer cost per GPU hour, but cost per unit of useful AI output delivered at scale in production settings. Achieving this overall impact requires a shift toward system-level thinking, where efficiency, architecture, and transparency are treated as primary drivers of both performance and economics.
AI leaders that make this shift will not only reduce cost, but also unlock greater performance and scalability from their AI investments. In large-scale AI environments, efficiency is not simply an optimization. It is the foundation of sustainable advantage.
Organizations that make this shift will achieve higher utilization of their AI resources, reduce waste across the stack, and materially lower total cost of ownership. In large-scale AI, efficiency is the primary driver of both performance and economics. And the platforms designed with that principle in mind will lead the next generation of enterprise AI.
Read the full report by Signal65 to learn more about CoreWeave’s TCO over a 3-year period for small, medium, and large workloads.


.avif)








